
1 Introduction
In this paper, we want to tackle the Molyneux question thoroughly, by addressing it in terms of both ordinary perception, the perception of concrete objects out there, and pictorial perception, the perception one has when facing pictures understood as such, i.e., in their figurative value: if a congenitally blind person recovered sight, could she recognize visually the 3D shapes she already recognized tactilely, both when such shapes are given to her directly and when they are given to her pictorially, i.e., as depicted shapes? Philosophers have been trying to tackle the question by means of a priori reflections on the relationship between sense modalities such as touch and vision. Yet it is perhaps time to face the question by means of a posteriori research. Indeed, we want to claim that empirical evidence suggests that the question can be positively answered both in the case of ordinary perception and in the case of pictorial perception. For in the former case, such evidence shows that perception of 3D shapes is supramodal; namely, it can be equivalently achieved in different sense modalities, notably touch and vision, independently of the sensory input such shapes are accessed. While in the latter case, such evidence shows that, as regards both sight and touch, one can satisfy the condition for depicted shapes to be grasped by that perceiver in the picture’s subject, i.e., what the picture presents, although clearly, just as that subject is typically not located where the perceiver is, such shapes are typically not instantiated where that perceiver is (just as Mona Lisa herself, the subject of Leonardo’s La Gioconda, Mona Lisa’s face is not at the Louvre, where a spectator enjoys Leonardo’s masterpiece). This condition states that the picture’s vehicle, i.e., the typically 2D physical basis of a picture, is enriched by adding to its properties the 3D grouping properties that allow for a figure/ground segmentation to be performed in that vehicle’s elements. In a nutshell, since the vehicle’s grouping properties are perceived supramodally, the depicted 3D shapes are also modally-indifferently grasped. In Section 1, we will address the case of ordinary perception; in Section 2, we will focus on pictorial perception.
2 A supramodal account of ordinary perception
The Molyneux question asks whether an individual who has recently gained the ability to see could promptly recognize three-dimensional objects such as cubes and spheres, which were previously familiar only through touch, solely visually, i.e., by solely using their sense of sight (for discussion, see, for example, Degenaar et al., 2024; Ferretti & Glenney, 2020; Matthen & Cohen, 2020).
As regards 3D objects, a positive answer to this question is encouraged by neuroscience findings indicating a robust functional equivalence, in the sighted, between vision and touch (for discussion, see Calzavarini & Voltolini, 2023). Granted, touch acquires information sequentially from fingertips, whilst vision processes it in a parallel and more holistic manner. Despite these differences, the outcome – behavioral performance in object recognition tasks – is surprisingly comparable across both modalities (for review, see Lacey & Sathian, 2014). Critically, behavioral findings suggest that tactile recognition, much like visual recognition, has a perspectival nature, something similar to a ‘point of view’, being influenced by the object’s orientation relative to the observer. In a seminal study, Newell et al. (2001) have shown that when neurotypical subjects attempt to recognize unfamiliar objects assembled from Lego blocks, their performance deteriorates significantly if the object is rotated 180° along any axis. Similarly, both tactile and visual presentations of objects suggest that there is an optimal orientation or ‘canonical perspective’ that facilitates recognition (Woods et al., 2008). Functional equivalence between vision and touch is also supported by findings that individuals who learn to identify new objects visually can often apply this recognition to tactile experiences, and the reverse is also true (Lacey et al., 2007; Lawson, 2009; Norman et al., 2004). Additionally, the way objects are perceived as similar is consistent across these sensory modalities (Cooke et al., 2007; Gaissert et al., 2010).1
Furthermore, a growing body of experimental research using diverse methodologies such as fMRI, TMS, and studies on individuals with brain damage points to significant neural overlap between the visual and tactile modalities, reinforcing the thesis of their functional equivalence (for reviews, Lacey & Sathian, 2014; Ricciardi et al., 2014). The convergence of visual and tactile input appears to peak within the so-called lateral occipital complex (LOC), located in the ventral visual pathway between the occipital and inferior temporal gyri.2 Traditionally viewed as a structure dedicated to visual shape recognition (Grill-Spector et al., 2001), subsequent neuroimaging research has revealed that the LOC also engages when shapes are explored tactilely in individuals with normal vision (Amedi et al., 2002, 2007; James et al., 2002). For example, James et al. (2002) have shown that LOC is active when normal individuals are seeing and touching objects. Similarly, Amedi et al. (2002, 2007) have shown that recognizing objects’ shapes (vs. textures) in both visual and haptic modalities increases activity in LOC. Moreover, LOC appears to show increased (‘multisensory’) responses when visual and tactile stimuli are presented in combination (Kim & James, 2010).
In the early univariate fMRI studies, the amount of neural activation (i.e., BOLD contrast) was the only criterion to demonstrate the intrinsic multimodality of the neural structures involved in 3D shape processing (e.g., Amedi et al., 2002). A potential objection is that this methodology is only an indirect test of multimodality but is not revealing about the format of neural representations (e.g., Erdogan et al., 2016; Kiefer et al., 2023). Based on these data, the possibility is still open that LOC implements independent modality-specific representations for both visual and haptic shapes. Nevertheless, more recent studies in the multisensory field have made use of multivariate neuroimaging, which is standardly supposed to be informative about the format of neural representations at the neural population level (see, for instance, Calzavarini, 2024; Heinen et al., 2024; Kriegeskorte & Douglas, 2018; Ricciardi & Pietrini, 2024). Techniques such as cross-modal multivoxel pattern classification (MVPC) and cross-modal representational similarity analysis (RSA) have been used, respectively, to show that object shapes can be multisensorily decoded from activation in LOC (e.g., Pietrini et al., 2004) and elicit similar patterns of neural activity across vision and touch (e.g., Erdogan et al., 2016). Results of these multivariate studies converge in suggesting that representations of objects’ shapes [in LOC] are multisensory (i.e., with a significant degree of modality independence), implementing a “unique code [...] regardless of whether the sensory modality is vision or touch” (Erdogan et al., 2016, p. 18).
Another potential objection is that activations in LOC during haptic tasks might simply be the result of top-down involvement of visual imagery rather than direct activation by tactile input. Critically, however, these putative ‘visual’ neural regions respond to shape information also when people who cannot engage in visual imagery, such as congenitally blind individuals, are tactilely exploring 3D objects (Heimler & Amedi, 2020; for reviews, Lacey & Sathian, 2014; Ricciardi et al., 2014) In a pioneering study, Pietrini et al. (2004) used MVPC to investigate the neural activity of both normal and congenital/early blind individuals during visual and/or tactile recognition tasks. The study design involved 3D objects belonging to three different categories: bottles, shoes, and (3D models of) human faces (see \(\ref{fig:figure1}\)). In the haptic version of the task, both groups of subjects were asked to manipulate the objects and try to recognize their shapes, with sighted individuals being blindfolded. Results showed that, in sighted individuals, both visual and tactile shape recognition were associated with similar patterns of category-related patterns of activity in the LOC and nearby regions in the ventral temporal cortex (see again \(\ref{fig:figure1}\)). Furthermore, as the authors observe, “blind subjects also demonstrated category-related patterns of response in this ‘’visual’’ area, and in more ventral cortical regions in the fusiform gyrus, indicating that these patterns are not due to visual imagery and, furthermore, that visual experience is not necessary for category-related representations to develop in these cortices.” (Pietrini et al., 2004, p. 5658).
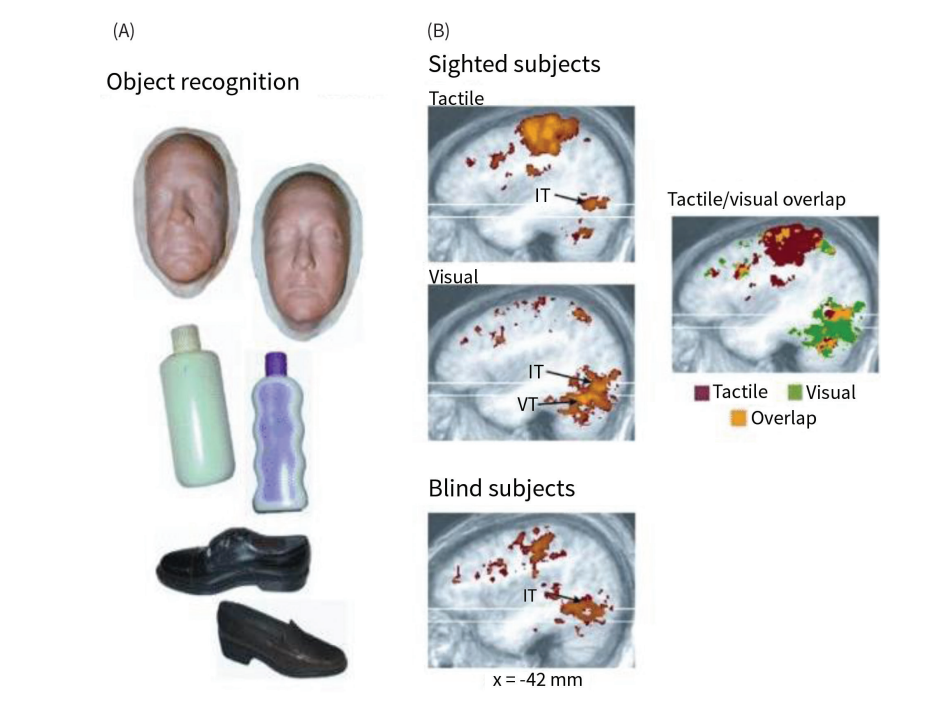
These results indicate a significant overlap of the neural structure involved in 3D shape processing, notably the LOC, across individuals with typical vision and the early and even congenitally blind. Interestingly, the role of the LOC in the recognition of 3D shapes appears to extend beyond visual and tactile senses. This region also activates in sighted and blind individuals in response to ‘sensory substitution’ systems that convert geometrical information into an auditory stream via specific algorithms (e.g., Amedi et al., 2007). Moreover, it has been recently shown using MVPC that sounds belonging to four different semantic categories (faces, body parts, artificial objects and scenes) can be decoded from neural activity in the ventral-temporal cortex of blind individuals (Hurk et al., 2017; Mattioni et al., 2020; Peelen & Downing, 2017). Based on these and similar results, several researchers have argued that LOC does not have a strictly visual profile but rather implements a modality-invariant (or supramodal) representation of object shape (see, e.g., Lacey & Sathian, 2014; Pietrini et al., 2004; Ricciardi et al., 2014). This suggests that perception of object 3D shapes is inherently neither solely visual nor tactile but rather supramodal, transcending specific modalities, notably in the sense of being input-independent. This notion aligns with the increasingly accepted meta-modal or supramodal paradigm in neuroscience, according to which the organization of the brain is primarily driven by the type of sensory computation performed (e.g., shape or motion processing) rather than by the traditional distinction into sensory (visual, auditory, tactile, olfactory, gustatory) and motor modalities (Calzavarini, 2021, 2024; Heimler & Amedi, 2020; Pascual-Leone & Hamilton, 2001; Ricciardi et al., 2014).
A potential complication for the conclusion that perceptual apprehension of the shapes of objects and their 3D depth ratio is supramodal is due to cortical functional plasticity which is known to follow sensory loss in congenital blindness (for review, see Bedny, 2017). It might be argued that neural regions sensitive to vision in the sighted may functionally reorganize to respond to touch in the blind, without this indicating that the same supramodal processes are involved in 3D shape processing across normal and blind individuals (e.g., Kiefer et al., 2023). Nevertheless, as observed by several scholars (e.g. Calzavarini, 2024; Makin & Krakauer, 2023; Ricciardi & Pietrini, 2024), plasticity for high-level ‘visual’ regions such as LOC is strongly constrained by their pre-determined function (e.g., shape processing), suggesting that, in congenital blindness, the specific computations of these areas are preserved even if they are now triggered by input from another modality (e.g., touch). This suggests that plasticity after a sensory loss cannot override the original functional profile of a region (e.g., transforming a visual region into a tactile region) but is “better interpreted as upregulation of a more general input-agnostic computational capacity that then favours one input over another” (Makin & Krakauer, 2023, p. 4). In particular, for regions such as LOC, “unmasking of a latent [supramodal] capacity that is present in sighted individuals is a more plausible mechanism than positing a qualitative change in a visual area to a tactile one” (Makin & Krakauer, 2023, p. 12).
In the context of Molyneux’s problem, these insights suggest that if the brain is inherently capable of processing shapes in a supramodal way, a newly sighted individual might possess the neural foundation necessary to recognize 3D shapes seen for the first time, provided that the latent capabilities of their ‘visual’ cortex can be quickly upregulated or unmasked through exposure and experience. Note that this conclusion appears to be supported by the few neuroscientific investigations concerning individuals who have recovered sight after congenital or early blindness (e.g., Chen et al., 2016; Held, 2009; Held et al., 2011; for a review, see Occelli, 2020). Results of these studies converge in showing that, right after the acquisition of sight, subjects show an almost complete inability to transfer tactile recognition to the visual modality (Chen et al., 2016; Held, 2009; Held et al., 2011). Nevertheless, this visuo-tactile transfer ability is quickly recovered after a brief period of training, demonstrating that the “two senses are prearranged to immediately become calibrated to one another” (Chen et al., 2016, p. 1069).3 As observed by Occelli,
if […] patients are observed while performing the task at varying delays after the surgical procedure, even a few hours later, then a positive answer to Molyneux’s question appears legitimate. This evidence points to a very fast acquisition of the capability to establish supramodal visuotactile representations through experience […]. Likely, this evidence is the behaviorally observable result of a very rapid unmasking of pre-existing connections between the occipital cortex and the other sensory areas (Occelli, 2020, p. 229).4
3 A supramodal account of pictorial perception
Once we have been able to show that ordinary perception allows one to have a supramodal grasping of 3D shapes, one may wonder whether the same works for another form of perception, pictorial perception, so as to have an analogous solution to Molyneux’s question not only as regards ordinary 3D shapes, but also as regards depicted 3D shapes, which, unlike ordinary 3D shapes, are typically not where the perceiver is. As we will see, there is a good chance to answer this doubt affirmatively.
Unlike ordinary perception, which is the perception of concrete objects out there, pictorial perception is a complex form of perception, for it addresses complex items; namely, pictures understood as such, i.e., in their figurative value. As is well known, in many occasions (Wollheim, 1980, 1987, 1998, 2003a, 2003b) Richard Wollheim has claimed that pictorial perception is a genuine form of perception, seeing-in, which is however sui generis because of its twofoldness. On the one hand, in its configurational fold (CF) seeing-in is addressed to the picture’s vehicle, i.e., the physical basis of a picture. On the other hand, in its recognitional fold (RF) seeing-in is also addressed to the picture’s subject, i.e., what is presented by that picture. For Wollheim, such folds are inseparable. Indeed, as he explicitly says (1987, p. 46), neither fold is identical with the perception of its respective object, the vehicle and the subject, taken in isolation. In this respect, one may take seeing-in as a genuine fusional state in which the folds are not only such that the RF depends on the CF – the former cannot exist if the latter does not exist as well (Hopkins, 2008), but also is compenetrated with it (Voltolini, 2020a).
Now, few people doubt that the seeing-in’s CF is genuinely perceptual. For the seeing-in’s bearer faces the CF’s object, the vehicle. Yet some people doubt (e.g., Dorsch, 2016; Walton, 1993) that the seeing-in’s RF is such. For, typically at least, the seeing-in’s bearer does not face the RF’s object, the subject. Obviously, while facing at Louvre Leonardo’s La Gioconda, the enigmatic woman in front of a Mediterranean landscape one sees in is not there, for she is nowhere. Yet even while standing at Windsor in front of a portrait of Charles III, the prestigious member of the Royal Family one sees in it is not there, where the portrait is hung. Granted, there are ways for justifying Wollheim’s claim. For example, one may say that the RF is a form of knowingly illusory perception, in which the seeing-in’s bearer knowingly illusorily perceives the vehicle as the subject (Voltolini, 2015). In such a case, one would have a sort of controlled hallucination of the subject, just as in the case of the Hermann grid, where at the crossing of white lines embedded into black squares, one seems to see gray spots that are not there (\(\ref{fig:figure2}\)). For clearly enough, the controlled hallucination that leads one to see such spots depend on the particular arrangement of the figure’s main constituents, i.e., its black squares. For if such squares differed in their arrangement, the spots would no longer visible (\(\ref{fig:figure3}\)).5


Anyway, what counts for our present purposes is that such a claim can be supported by better understanding how in seeing-in the CF compenetrates the RF. For this will allow one to understand how depicted 3D shapes can be grasped supramodally in that form of perception. Let us see.
To begin with, the seeing-in’s CF differs from the perception of the picture’s vehicle in isolation, since it has an enriched content, Indeed, it grasps not only the vehicle’s low-level properties – primarily, its colors and its 2D shapes – but also certain higher-level properties that depend on such properties (the latter cannot be instantiated if the former are not instantiated as well); namely, the grouping properties according to which such properties are arranged. Grouping properties are indeed the properties for an item’s elements – the vehicle low-level properties, in this case – to be organized along a certain direction in a certain dimension. One can see such properties at work already in cases of simple ambiguous figures such as the Mach figure, which can be seen either as a diamond or as a tilted square, depending on which symmetry axes are chosen in order to organize the figure’s array. Such axes remain the same even if the figure is rotated. Clearly enough, grouping properties are higher-level properties. For first, they depend on low-level properties – they would not be instantiated if some low-level properties (primarily, colors and shapes) were not instantiated as well – without supervening on them, as ambiguous figures clearly show. For example in the afore-mentioned Mach figure, its grouping organization changes, even if its low-level properties (primarily, its colors and shapes again) remain the same (Wittgenstein, 2009, II, xi, §247). Second and connectedly, grouping properties can be selectively lost in perception. As Wittgenstein again stressed (2009, II, xi, §257), one can be blind with respect to such properties (aspect-blindness), without being blind with respect to any low-level property (unlike, say, someone suffering from achromatopsia).
In this respect, grouping properties arranging elements in the third dimension are essential for seeing-in, which makes it the case that a basically flat object, the picture’s vehicle, is perceived as presenting a 3D scenario. For they allow such elements of the picture’s vehicle to be arranged along a figure-ground 3D segmentation, in which the elements so arranged standing in the front partially occlude the elements so arranged standing on the back, by virtue of their ascribed 3D shapes. As vividly happens in the case of ‘aspect dawning’- pictures, those in which the figurative character of a picture ‘lights up’ only after a while. For in the case of such a picture, one can clearly realize how a 3D-level figure/ground organization of its vehicle’s elements emerges out of the 2D level characterizing the fact that the vehicle is a basically flat object. For example, in the following picture (\(\ref{fig:figure4}\)), all of a sudden one arranges into a figure-ground segmentation the black-and-white 2D spots one has been grasping there for a long while. This grouping segmentation allows one to grasp certain 3D horseish silhouettes standing some on the front and some others on the back, as partially occluded by the former in virtue of their ascribed 3D shapes.

Once one gets such an enriched perception of the picture’s vehicle in the seeing-in’s CF, one can also grasp the 3D picture’s subject in the seeing-in’s RF, which shows how the two folds are compenetrated. What one grasps in the RF is indeed a 3D scene (Nanay, 2022), in which certain objects are on the foreground and others on the background. Now, not only the spatial relationships between such objects, but also their 3D shapes, recapitulate both the spatial relationships and the 3D shapes ascribed to the silhouettes grasped in the CF. To come back to the previous example of the ‘aspect dawning’ picture of \(\ref{fig:figure4}\), the horses that one grasps in the seeing-in’s RF with that picture recapitulate in their structure both the spatial relationships and the 3D shapes ascribed to the horseish silhouettes that one grasps in the seeing-in’s CF with that picture.
Now, typically at least, the 3D shapes of the items that are captured in a seeing-in experience are grasped visually. Yet nothing prevents them from being captured in another sense modality, notably the tactile one. As Lopes (1996), Voltolini (2015) and Calzavarini and Voltolini (2023) have theorized and Kennedy (1993) has empirically confirmed, there are tactile pictures, in which from the perceptual point of view everything works just as in visual pictures.6 In addressing such pictures, on the hand, among the various alignments that a tactile perceiver makes of the elements of those pictures’ vehicles, that perceiver tactilely grasps the figure-ground segmentations in such elements. Those segmentations are modulated by the 3D shapes that perceiver ascribes to such elements. So, the relevant vehicle’s grouping properties that one can grasp visually can be also grasped tactilely, hence in a modality-independent way. On the other hand, by virtue of the above grouping operation, that perceiver also ends up with tactilely grasping a 3D scene that is not there. Hence, the perceiver clearly entertains a touching-in twofold perception of the picture that structurally works just as an ordinary seeing-in perception of that picture: the ascribed 3D segmentations are tactilely grasped in the CF, the 3D scenario is tactilely grasped in the RF, of a touching-in perception.
Now, as it has empirically shown by various studies in cognitive psychology, tactile pictures are so grasped not only by sighted people possibly blindfolded, but also by congenitally blind people. In addressing the vehicle of a picture raised in relief, the latter people are able to tactilely grasp its element’s alignments, hence to so ascribe such elements the 3D figure-ground segmentations of such elements that explain why occlusions affecting such elements are also grasped (Kennedy, 1997, 2000; Kennedy & Domander, 1984; Kennedy & Juricevic, 2006). Hence, those people ascribe to such elements certain 3D shapes. Such an ascription further explains why such people are also able to grasp in that picture’s subject the proper 3D shapes of the items constituting the scene that they perceive even if they do not face it. This ability mirrors the ability they exhibit in ordinary tactile perception, in which they can grasp the proper 3D shapes of the items of the scenes that they face (Tinti et al., 2018). Thus, in the end, congenitally blind people are able to entertain a touching-in twofold pictorial perception of that picture that structurally works just as an ordinary seeing-in perception of that picture.
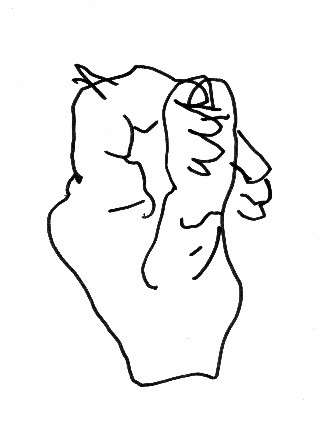
If the above is the case, the grasping of the 3D depicted shapes is supramodal as well, since such shapes are possibly accessed either visually or tactilely. Hence, it is quite likely that there is a solution to the pictorial version of Molyneux’s puzzle that mirrors the one we have provided for its ordinary version. If she recovered sight, would a blindfolded person visually recognize the very same depicted shapes in a certain bas-relief picture that she was able to detect when addressed that picture tactilely? There are good chances to answer this question in the affirmative. Since touching-in structurally works just as seeing-in, a congenital blind person tactilely perceives the depicted 3D shapes she would able to visually perceive if she recovered sight. For example, as regards a bas-relief picture, a congenitally blind person may be able to touch in it the 3D shape of a depicted hand whose thumb partially occludes the other hand’s fingers by depictively standing in front of them. Now, if all of sudden she indeed recovered her sight, she would be able to grasp exactly the same 3D depicted shape. As is also proven by the fact that even in her present blindness, she may depict a similar picture (\(\ref{fig:figure5}\)) for sighted people to be seen-in (Kennedy, 1993; see also D’Angiulli et al., 1998; Kennedy & Bai, 2002; Pawluk et al., 2010).
Note that a positive answer to the Molyneux question in its pictorial form cannot be conclusively established based on extant neuroscientific research. To date, for example, there are no neuroimaging studies showing that the neural structures involved in the recognition of visual pictures are at least partially overlapping with those involved in the recognition of tactile pictures, and that these neural structures are the same in sighted and congenitally blind individuals (for discussion, see Calzavarini & Voltolini, 2023). The only neuroimaging (fMRI) study that has investigated the neural activation during the recognition of seemingly tactile pictures (Stoesz et al., 2003) has used stimuli with modest figurative value (tactile tables representing letters “V” and “U”), which are unlikely to trigger robust front → behind grouping processes. So granted, only potential fMRI studies involving tactile pictures with greater figurative complexity (e.g., raised-line drawings of objects and scenes seen in perspective; see Calzavarini & Voltolini (2023)) might be relevant to this issue. More critically, most of the neuroscientific investigations of shape processing in individuals who have recovered sight after blindness have used only 3D objects (e.g., Lego blocks) as stimuli (Chen et al., 2016; e.g. Held et al., 2011). Interestingly enough, a recent study by McKyton et al. (2015) indicates that, although newly sighted individuals can quickly recover the ability to recognize 2D pictorial stimuli, after 1 year they still are relatively unable to infer 3D shapes from pictorial cues such as occlusions and illusory contours. Yet, other studies indicate susceptibility to pictorial illusions such as Ponzo and Müller-Lyer immediately after sight onset (Gandhi et al., 2015), suggesting that the results by McKyton et al. (2015) might be due to the specific pictorial tests involved (for discussion, see Murray et al., 2015).7 Thus, more research is needed to provide conclusive positive proof for the supramodal pictorial perception hypothesis and, consequently, for a supramodal thorough account of the Molyneux question. Yet, on the basis of the present evidence, it is reasonable to assume that such a proof is forthcoming. 8
4 Conclusions
Let us take stock. First of all, there is a huge amount of empirical evidence showing that ordinary perception of 3D shapes is supramodal. If this is the case, then the Molyneux question has a positive answer: the same 3D shapes that one can recognize tactilely can be also recognized visually. Moreover, similar empirical considerations show that congenitally blind people are able to perform by means of touch the same 3D grouping operations with basically 2D pictorial vehicles that ordinary sighted people perform by means of vision. So, the pictorial vehicle’s grouping properties can be grasped supramodally as well. Hence, such a performance allows them to have a touching-in experience pretty alike to the ordinary seeing-in experience. Thus, there is a great chance that also a pictorial version of the Molyneux question can be answered positively: the former people are able to tactilely grasp the depicted 3D shapes that they would grasp visually, once they recovered sight.
References
Note that functional equivalence from vision and touch could also be found when lower-level perceptual features, such as edges, connectedness and texture, are involved (see, e.g., Plaisier et al., 2008, 2017; 2009).↩︎
Granted, LOC is not the only brain region that is supposed to be involved in visual shape recognition. In classical models of visual recognition (see, e.g., Kravitz et al., 2013), the transformation of 2D retinal input into a 3D representation along the visual pathways is a complex process that begins in the primary visual cortex (V1), which elaborates elementary features such as edges and orientation. From V1, visual information proceeds along two functionally distinct streams: the dorsal stream, which goes towards the parietal lobes and is critical for motion and spatial processes, and the ventral stream, which extents in the temporal lobe and is involved in object recognition and shape perception. Within the ventral stream, visual information is progressively integrated and transformed in higher visual areas, such as V2 and V4, which processes more complex features like contours, shapes, and colors. This hierarchical processing culminates in the lateral occipital complex (LOC), where the visual system assembles these lower-level features into coherent 3D object representations, enabling the perception of depth, form, and object identity.↩︎
Indeed, the recognition of static 3D forms after sight may require more extensive experience and cortical reorganization compared to other visual processes. For example, a recent study by Orlov et al. (2021) has reported the case of 23 newly sighted children who quickly recovered the ability to infer the direction of global motion but maintained significant difficulties in recognizing shapes in slit-viewing conditions, which required them to integrate fragmented visual information over time to recover the global shape. In addition, the study indicates that “shape recovery could only be carried out after the global-motion vector was extracted” (Orlov et al., 2021, p. 3165). These results not only suggest that “the motion-processing pathways are likely to be more resilient to long-term visual deprivation than the form-processing pathways” (ib.), but also that the reliance on motion cues might be an essential component of 3D shape recognition. Note, however, that the study by Orlov et al. (2021) focuses on anorthoscopic vision, which requires participants to recognize shapes that are only partially visible at any given moment as they move behind a narrow slit. This setup is intrinsically more closely aligned with the functioning of the dorsal pathway, which processes motion and spatial relationships over time, and might not be ideal for testing 3D shape recognition. Thus, more research is needed on this issue.↩︎
If perception of 3D shapes is supramodal, there is no need to appeal to mental imagery in order to ascribe a congenitally blind person the capacity to visually grasp the same 3D shapes she can already grasp tactilely, as Nanay (2023, pp. 104–106; see also 2020) instead claims.↩︎
Granted, there are reasons to say that the perception of the Hermann grid is not already a pictorial perception, since no proper 3D scene seems ultimately to be grasped in it, as if no RF would occur in that perception. For what enables that scene to be grasped, hence a genuine RF to emerge in a proper seeing-in perception, is its subject’s conceptualization: cf. Voltolini (2015, 2020b). This is apparently consistent with the observation that the Hermann grid is traditionally considered to be a very low-level psychological phenomenon, being created at the retinal level and not at a cortical level of stimulus processing (Baumgartner, 1960). Note, however, that this retinal account has been revisited more recently by Schiller and Carey (2005), who suggest that the Hermann grid illusion is primarily a cortical phenomenon, due to “the manner in which S1 type simple cells […] in primary visual cortex respond to the grid” (2005, p. 1375).↩︎
Hopkins (2000, 2004) has claimed that there cannot be tactile pictures, since they do not seem to grasp the picture’s subject from a vantage point of view, as even for Wollheim (1980) seems to be fundamental for seeing-in. Yet this claim has been both theoretically (Calzavarini & Voltolini, 2023) and empirically (Gallace & Spence, 2014) criticized, also because, as we saw in the previous Section, already in ordinary perception touch seems to be sensitive to perspectivality.↩︎
McKyton et al. (2015) used a “odd-ball task” in which participants were asked to find an odd target among an array of elements. Conditions in this study included low-level tasks (shape recognition based on color, size or contour) and mid-level tasks (shape recognition based on 3D pictorial clues: occlusion, shading, box, and illusory contours). In their commentary on this article, Murray et al. (2015, p. R999) argued that “the oddball discrimination tasks used by McKyton et al. […] may have tapped into experience-dependent processes […] in contrast to the illusions reported in Gandhi et al. […]”, and this might explain the apparently conflicting results across the two studies.↩︎
Note that a similar conclusion can be drawn for pictorial production, that is, the ability to produce drawings. A fascinating study conducted by Amedi et al. (2008), for example, reported the case of E.A., an early blind artist capable of creating highly detailed drawings of objects or scenes that are easily recognizable by sighted individuals. The study employed fMRI to explore the neural mechanisms underlying E.A.’s ability to convert 3D objects explored through touch into 2D drawings. The neural activity observed during the drawing process involved several ‘visual’ areas, including the LOC, supporting a supramodal profile of pictorial production. A recent study by Tian et al. (2024) has tested the drawing ability (among other things) of a group of early blind individuals, showing that the blind can produce recognizable drawings, especially for tools, which they had rich tactile experiences with. The absence of visual experience, however, impacted on the ability to draw animals, with blind participants’ drawings being less recognizable than those of sighted participants. These results suggest that, while tactile experience can compensate for the lack of vision in producing pictorial stimuli, vision might still be crucial for in cases where tactile information is less available, such as in the case of animals.↩︎